本文仅做学习总结,如有侵权立删
[TOC]
一、理解RDD
RDD可以被抽象地理解为一个大的数组,但是这个数组是分布在集群上的。
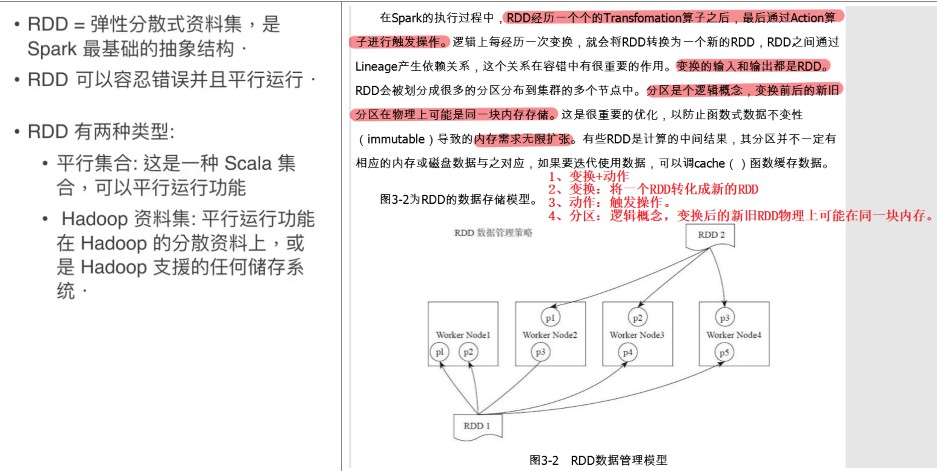
二、RDD的生命周期
创建—变换—动作(结束)
三、RDD依赖
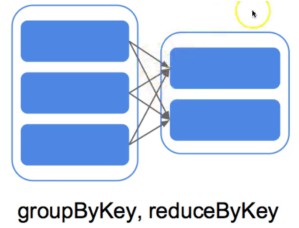
1、窄依赖(RDD)—–原地变换,不需要shuffle【即各个RDD之间不需要统计】
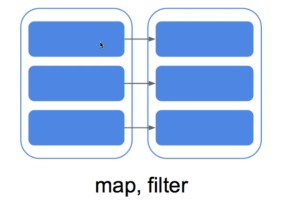
2、宽依赖(RDD)—–需要shuffle,与其他RDD交换资料,时间消耗长。
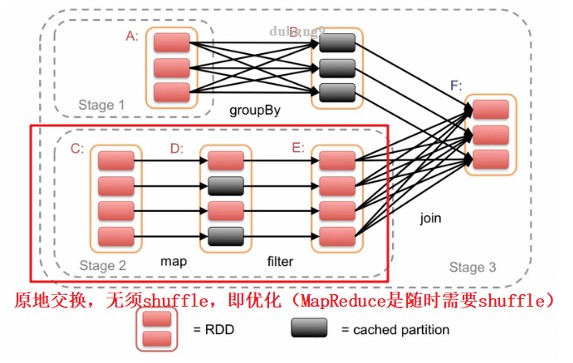
3、任务优化,如
四、RDD的基本操作
RDD可以有两种计算操作算子:Transformation(变换)与Action(行动)。

1、基本的RDD
(1)建立RDD
1 | wordsList = ['cat','ele','rat','rat','cat'] |
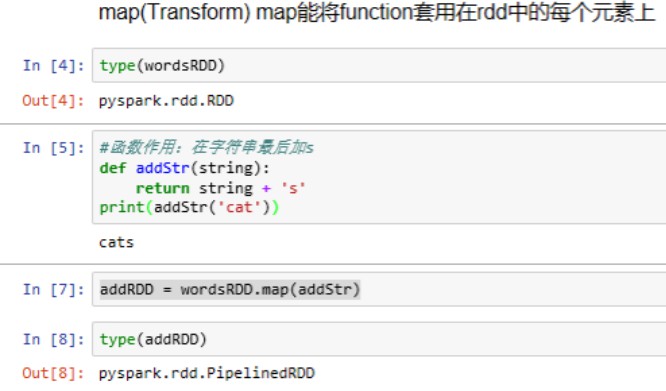
#建立RDD wordsList = ['cat','ele','rat','rat','cat'] wordsRDD = sc.parallelize(wordsList , 4)
#计算法每个单词的长度 wordsRDD.map(len).collect()
(2)转换操作
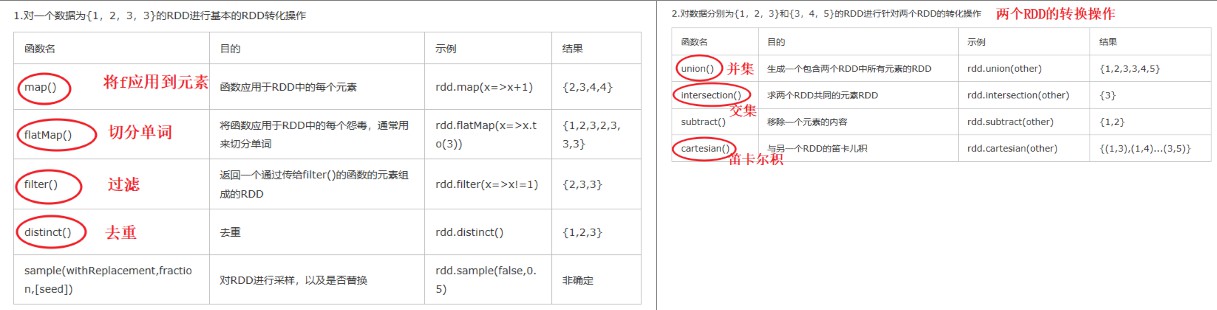
(3)动作操作
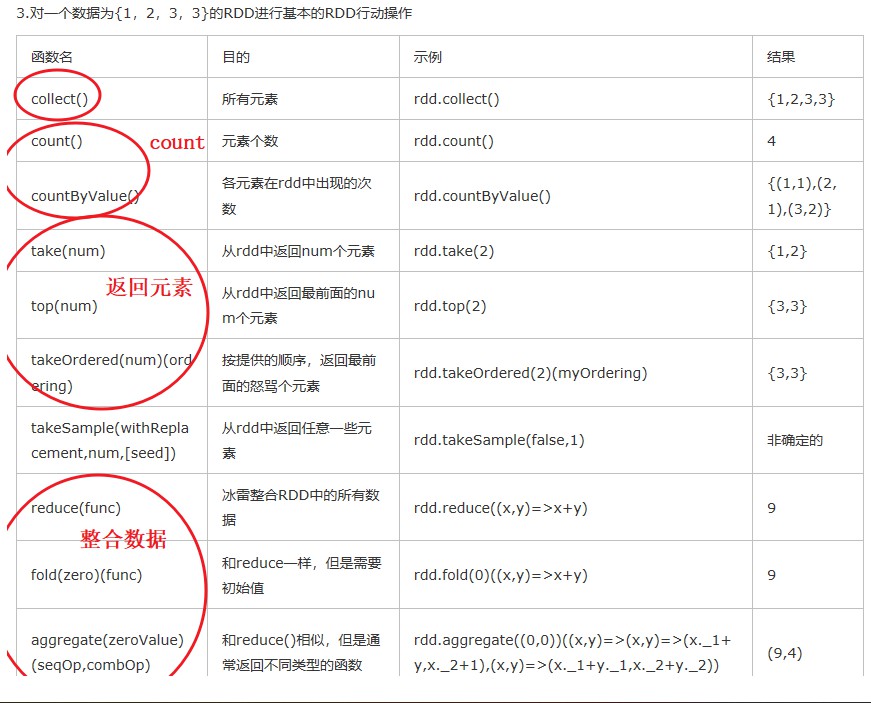
(4)通过pipe方法调用系统命令操作RDD
每个输入分区的所有元素被当做另一个外部进程的标准输入,输入元素由换行符分隔。
最终结果由该外部进程的标准输出生成,标准输出的每一行产生输出分区的一个元素。
例子:将每个分区传递给wc命令。每个元素将作为一个输入行,因此执行行计数,将得到每个分区的总行数:
1 | words.pipe("wc -l").collect() |
(5)mapPartitions:每次处理一个分区
Spark 在实际执行代码时是基于每个分区运行的,所有map函数只是mapPartitions基于行操作的一个别名,
mapPartitions函数每次处理一个数据分区(可以通过迭代器来遍历该数据分区),不是具体的一行。
例子:为数据中的每个分区创建值“1”, 以下表达式中计算总和将得出我们拥有的分区数量:
1 | words.mapPartitions(lambda part:[1]).sum() #2 |
应用场景:将属于某类的值收集到一个分区中,然后对整个分组进行操作。
(6)mapPartitionsWithIndex:接收两个参数,一个位分区的索引和另一个为 遍历分区内所有项的迭代器。
mapPartitionsWithIndex应用场景:测试map函数是否正确运行。
1 | def indexedFunc(partitionIndex, withinPartIterator): |
(7)foreachPartition:与mapPartitions函数类似,但不需要返回值
mapPartitions函数需要返回值才能正常执行,但foreachPartition函数不需要。
foreachPartition函数仅用于迭代所有的数据分区,与mapPartitions的不同在于它没有返回值,适合写入数据库操作(不需要返回计算结果)。
(8)glom: 将每个分区都转换为数组。
当需要将数据收集到驱动器并想为每个分区创建一个数组时,就很适合用glom函数实现。但会导致严重的稳定性问题,当有很大的分区或大量分区时,该函数会导致驱动器崩溃。
1 | spark.sparkContext.parallelize(["hello" , "words"], 2).glom().collect() |
2. 键值对PairRDD:算子中包含ByKey的都是针对PairRDD
(1)创建PairRDD
是一种以(key,value)方式存储的RDD。
pairRDD = wordsRDD.map(lambda x : (x , 1))
- keyBy:根据当前value创建key的函数。
1 | # 将单词中的第一个字母作为key, 然后Spark将该单词记录保存为RDD的value |
(2) 转换操作
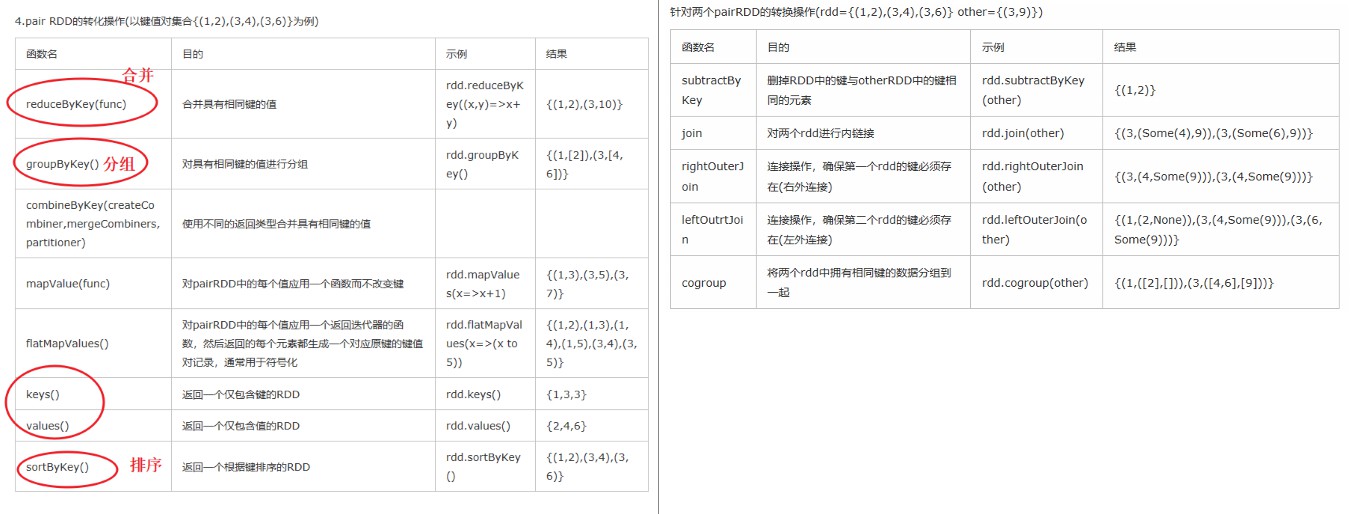
mapValue:只修改value,不修改key
1
2
3
4
5
6Keyword.mapValues(lambda word:word.upper()).collect()
# 结果:
'''
[('s', 'SPARK'),
('t'),'THE']
'''flatMapValues:在row(行)上进行flatMap操作来扩展行数
keys() / values():提取keys或value
sampleByKey:通过一个key来采样RDD
(3) 动作操作
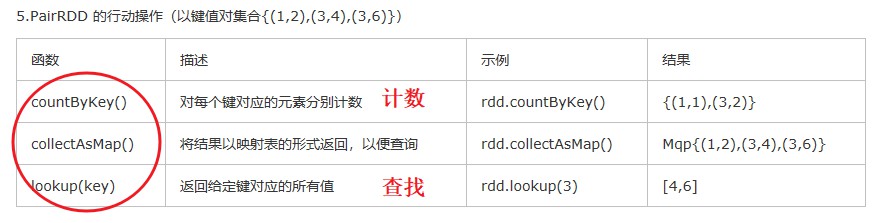
- lookup:查找某个key对应的value, 因为同一个key可能有多个value,例子:查找’s’时,将获得与该key相关的两个value, 即’Spark’和’Simple’
1 | keyword.lookup("s") |
一些小问题:
1、spark中的RDD是什么
概念:分布式数据集,**spark**中基本的数据抽象,代表一个不可变、可分区、元素可并行计算的集合。
2、RDD的五大特性:
①有一个分区列表,即能被切分,可并行。
②由一个函数计算每一个分片
③容错机制,对其他RDD的依赖(宽依赖和窄依赖),但并非所有RDD都要依赖。
RDD每次transformations(转换)都会生成一个新的RDD,两者之间会形成依赖关系。在部分分区数据丢失时,可通过依赖关系重新计算丢失的数据。
④key-value型的RDD是根据哈希来分区的,控制Key分到哪个reduce。
⑤每一分片计算优先位置,比如HDFS的block的所在位置应该是优先计算的位置。
3、概述一下spark中的常用算子区别(map、mapPartitions、foreach、foreachPartition)
| map | 遍历RDD,将函数f应用于每一个元素,返回新的RDD | transformation算子 |
|---|---|---|
| mapPartitions | 用于遍历操作RDD中的每一个分区,返回生成一个新的RDD | transformation |
| collect | 将RDD元素送回Master并返回List类型 | Action |
| foreach | 用于遍历RDD,将函数f应用于每一个元素,无返回值 | action算子 |
| foreachPartition | 用于遍历操作RDD中的每一个分区。无返回值 | action算子 |
| 总结 | 一般使用mapPartitions或者foreachPartition算子比map和foreach更加高效,推荐使用。 |
4、谈谈spark中的宽窄依赖
- RDD和它依赖的父RDD的关系有两种不同的类型,即窄依赖和宽依赖。
- 宽依赖:指的是多个子RDD的Partition会依赖同一个父RDD的Partition分区【需要shuffle,与其他RDD交换资料】 例如 groupByKey、 reduceByKey、 sortByKey等操作会产生宽依赖,会产生shuffle
- 窄依赖:指的是每一个父RDD的Partition最多被子RDD的一个Partition分区使用。【原地变换,不需要shuffle】 例如map、filter、union等操作会产生窄依赖
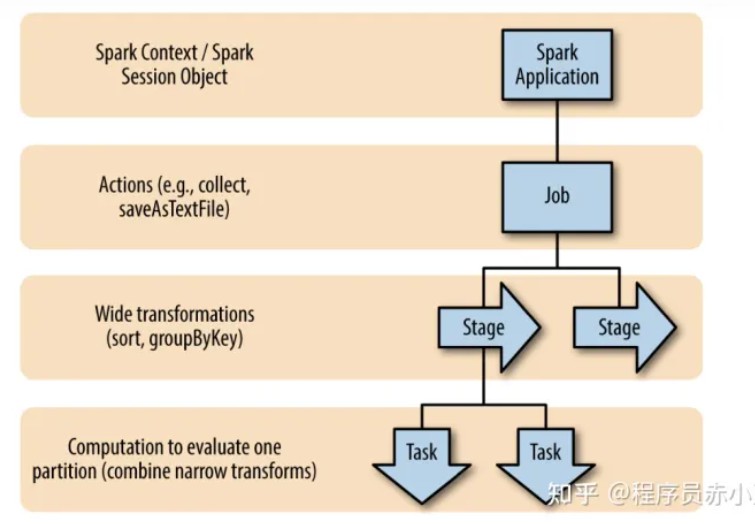
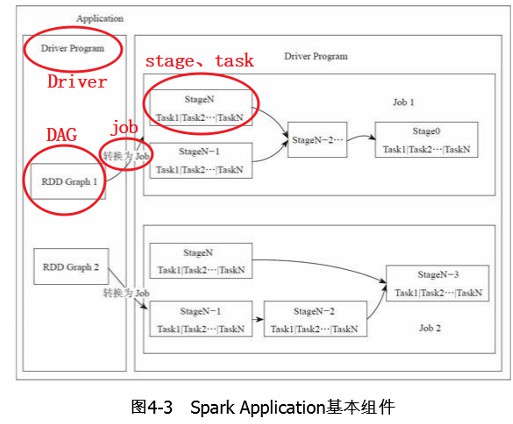
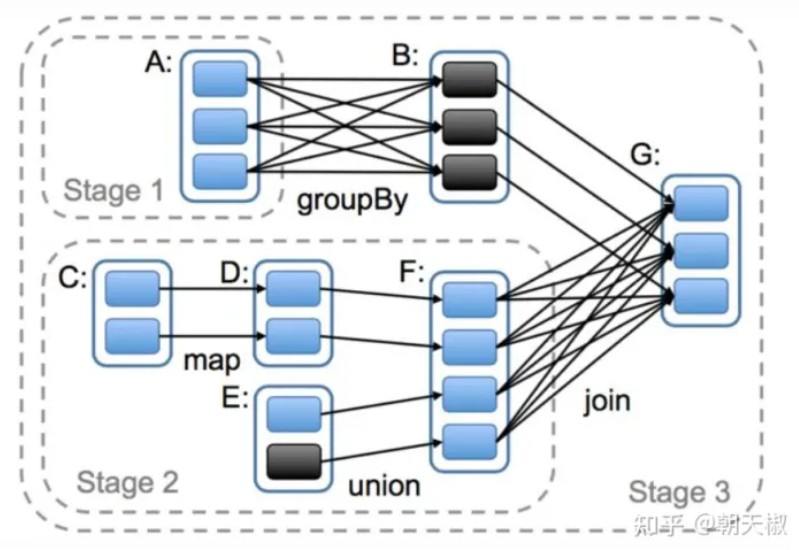
5、spark中如何划分stage
Stage划分的依据就是宽依赖,何时产生宽依赖,例如reduceByKey,groupByKey的算子,会导致宽依赖的产生。
| 先介绍什么是RDD中的宽窄依赖, |
|---|
| 然后在根据DAG有向无环图进行划分,从当前job的最后一个算子往前推,遇到宽依赖,那么当前在这个批次中的所有算子操作都划分成一个stage, |
| 然后继续按照这种方式在继续往前推,如在遇到宽依赖,又划分成一个stage,一直到最前面的一个算子。 |
| 最后整个job会被划分成多个stage,而stage之间又存在依赖关系,后面的stage依赖于前面的stage。 |
五、代码学习
1. 建立RDD
创建RDD的两种方法:
1 读取一个数据集(SparkContext.textFile()) : lines = sc.textFile(“README.md”)
2 读取一个集合(SparkContext.parallelize()) : lines = sc.paralelize(List(“pandas”,”i like pandas”))

#take操作将前若干个数据汇集到Driver,相比collect安全
1 | # 创建RDD |
- 从text中读取,read.text

- 从csv中读取:read.csv

- 从json中读取:read.json

2. RDD与Dataframe的转换
(1)dataframe转换成rdd:
法一:datardd = dataDataframe.rdd
法二:datardd = sc.parallelize(_)
(2)rdd转换成dataframe:
dataDataFrame = spark.createDataFrame(datardd)



3. rdd函数
| mapReduce | 说明 |
|---|---|
rdd.map(func) |
将函数应用于RDD中的每个元素并返回 |
rdd.mapValues(func) |
不改变key,只对value执行map |
rdd.flatMap(func) |
先map后扁平化返回 |
rdd.flatMapValues(func) |
不改变key,只对value执行flatMap |
rdd.reduce(func) |
合并RDD的元素返回 |
rdd.reduceByKey(func) |
合并每个key的value |
rdd.foreach(func) |
用迭代的方法将函数应用于每个元素 |
rdd.keyBy(func) |
执行函数于每个元素创建key-value对RDD |
1 | pairRDD=sc.parallelize([('a',7),('a',2),('b',2)]) # key-value对RDD |
(1)map操作
(2)collect操作

| 提取 | 说明 |
|---|---|
rdd.collect() |
将RDD以列表形式返回 |
rdd.collectAsMap() |
将RDD以字典形式返回 |
rdd.take(n) |
提取前n个元素 |
rdd.takeSample(replace,n,seed) |
随机提取n个元素 |
rdd.first() |
提取第1名 |
rdd.top(n) |
提取前n名 |
rdd.keys() |
返回RDD的keys |
rdd.values() |
返回RDD的values |
rdd.isEmpty() |
检查RDD是否为空 |
1 | pairRDD=sc.parallelize([('a',7),('a',2),('b',2)]) # key-value对RDD |
| 分组和聚合 | 说明 |
|---|---|
rdd.groupBy(func) |
将RDD元素通过函数变换分组为key-iterable集 |
rdd.groupByKey() |
将key-value元素集分组为key-iterable集 |
rdd.aggregate(zeroValue,seqOp,combOp) |
在驱动器上执行最终聚合,如果执行器的结果太大,则会导致驱动器出现内存错误并最终让程序崩溃。 第一个函数执行分区内聚合。 第二个函数执行分区间聚合。 |
| depth = 3 rdd.treeAggregate(0, maxFunc, addFunc, depth) |
基于不同的实现方法可以得到与aggregate相同的结果,创建从执行器到执行器传输结果的树,最后再执行最终聚合。多层级的形式确保驱动器在聚合过程中不会耗尽内存,这些基于树的实现通常会提高某些操作的稳定性。 |
rdd.aggregateByKey(zeroValue,seqOp,combOp) |
此函数与aggregate基本相同,但是基于key聚合而非基于分区聚合。起始值和函数的属性配置也都相同 |
| rdd.combineByKey | 不仅可以指定聚合函数,还可以指定一个合并函数。该合并函数针对某个key进行操作,并根据某个函数对value合并,然后合并各个合并器的输出结果并得出最终结果。 |
rdd.fold(zeroValue,func) |
|
rdd.foldByKey(zeroValue,func) |
使用满足结合律函数和中性的“零值”合并每个key的value,支持多次累积到结果,并且不能更改结果(0为加法,1为乘法) |
1 | pairRDD=sc.parallelize([('a',7),('a',2),('b',2)]) # key-value对RDD |
更好的解决方案:reduceByKey,非groupBykey
reduceByKey能够直接将资料根据key值聚合,减少多余的交换(shuffle)动作。reduce发生在每个分组,并且不需要将所有内容放在内存中
避免使用groupbykey,如果数据量过大,会造成内存溢出。每个执行器在执行函数之前必须在内存中保存一个key对应的所有value。
- spark中groupByKey 、aggregateByKey、reduceByKey 有什么区别?使用上需要注意什么?
(1)groupByKey()是对RDD中的所有数据做shuffle,根据不同的Key映射到不同的partition中再进行aggregate。
(3) distinct()也是对RDD中的所有数据做shuffle进行aggregate后再去重。
(2)aggregateByKey()是先对每个partition中的数据根据不同的Key进行aggregate,然后将结果进行shuffle,完成各个partition之间的aggregate。因此,和groupByKey()相比,运算量小了很多。
(4)reduceByKey()也是先在单台机器中计算,再将结果进行shuffle,减小运算量

| 选择数据 | 说明 |
|---|---|
rdd.sample(replace,frac,seed) |
抽样 |
rdd.filter(func) |
筛选满足函数的元素(变换) |
rdd.distinct() |
去重 |
1 |
|
| 排序 | 说明 |
|---|---|
rdd.sortBy(func,ascending=True) |
按RDD元素变换后的值排序 |
rdd.sortByKey(ascending=True) |
按key排序 |
| 统计 | 说明 |
|---|---|
rdd.count() |
返回RDD中的元素数 |
rdd.countByKey() |
按key计算RDD元素数量 |
rdd.countByValue() |
按RDD元素计算数量 |
rdd.sum() |
求和 |
rdd.mean() |
平均值 |
rdd.max() |
最大值 |
rdd.min() |
最小值 |
rdd.stdev() |
标准差 |
rdd.variance() |
方差 |
rdd.histograme() |
分箱(Bin)生成直方图 |
rdd.stats() |
综合统计(计数、平均值、标准差、最大值和最小值) |
1 | pairRDD=sc.parallelize([('a',7),('a',2),('b',2)]) # key-value对RDD |
| 连接运算 | 说明 |
|---|---|
rdd.union(other) |
并集(不去重) |
rdd.intersection(other) |
交集(去重) |
rdd.subtract(other) |
差集(不去重) |
rdd.cartesian(other) |
笛卡尔积 |
rdd.subtractByKey(other) |
按key差集 |
rdd.join(other) |
内连接 |
rdd.leftOuterJoin(other) |
左连接 |
rdd.rightOuterJoin(other) |
右连接 |
| rdd.cogroup(rdd1) | 连接 |
| rdd.zip(rdd1) | 组合两个zip, 将两个RDD的元素对应的匹配在一起,要求两个RDD的元素个数相同,且两个RDD的分区数也相同,结果会生成一个PairRDD |
1 | rdd1=sc.parallelize([1,1,3,5]) |
| 持久化 | 说明 |
|---|---|
rdd.persist() |
标记为持久化 |
rdd.cache() |
等价于rdd.persist(MEMORY_ONLY) |
rdd.unpersist() |
释放缓存 |
- cache后面能不能接其他算子,它是不是action操作?
Cache后可以接其他算子,但是接了算子之后,起不到缓存的作用,因为会重复出发cache。
Cache不是action操作。
- cache和pesist有什么区别?
(1)cache和persist都是用于将一个RDD进行缓存的,这样在之后使用的过程中就不需要重新计算了,可以大大节省程序运行时间;
(2)cache只有一个默认的缓存级别MEMORY_ONLY ,cache调用了persist,而persist可以根据情况设置其它的缓存级别;
(3)executor执行的时候,默认60%做cache,40%做task操作,persist最根本的函数,最底层的函数
- Spark为什么要持久化,一般什么场景下要进行persist操作?
为什么要进行持久化?
spark所有复杂一点的算法都会有persist身影,spark默认数据放在内存,spark很多内容都是放在内存的,非常适合高速迭代,1000个步骤
只有第一个输入数据,中间不产生临时数据,但分布式系统风险很高,所以容易出错,就要容错,rdd出错或者分片可以根据血统算出来,如果没有对父rdd进行persist 或者cache的化,就需要重头做。
以下场景会使用persist
1)某个步骤计算非常耗时,需要进行persist持久化
2)计算链条非常长,重新恢复要算很多步骤,很好使,persist
3)checkpoint所在的rdd要持久化persist,
lazy级别,框架发现有checnkpoint,checkpoint时单独触发一个job,需要重算一遍,checkpoint前
要持久化,写个rdd.cache或者rdd.persist,将结果保存起来,再写checkpoint操作,这样执行起来会非常快,不需要重新计算rdd链条了。checkpoint之前一定会进行persist。
4)shuffle之后为什么要persist,shuffle要进性网络传输,风险很大,数据丢失重来,恢复代价很大
5)shuffle之前进行persist,框架默认将数据持久化到磁盘,这个是框架自动做的。
| 分区 | 说明 |
|---|---|
rdd.getNumPartitions() |
获取RDD分区数 |
rdd.repartition(n) |
新建一个含n个分区的RDD,对数据进行重新分区,跨节点的分区会执行shuffle操作。对于map和filter操作,增加分区可以提高并行度。 |
rdd.coalesce(n) |
将RDD中的分区减至n个, coalesce有效折叠(collapse)同一工作节点上的分区,以便在重新分区时避免数据洗牌(shuffle)。存储words变量的RDD当前有两个分区,可以使用coalsece将其折叠为一个分区。 |
rdd.partitionBy(key,func) |
自定义分区 |
| rdd.repartitionAndSortWithinPartitions | 将对数据重新分区,并指定每个输出分区的顺序。 |
文件系统读写
1 | # 读取 |















 ‘
‘