本文仅做学习总结,如有侵权立删
https://blog.csdn.net/weixin_42331985/article/details/124126019
https://zhuanlan.zhihu.com/p/396809439
https://blog.csdn.net/czz1141979570/article/details/105877261/
[TOC]
Spark生态架构图
Spark简介
1. 概念

Spark:基于内存的迭代式计算引擎。
RDD:Resillient Distributed Dataset(弹性分布式数据集),是分布式内存的一个抽象概念。
DAG:Directed Acyclic Graph(有向无环图),反映RDD之间的依赖关系。
Executor:是运行在工作节点(WorkerNode)的一个进程,负责运行Task
应用(Application):用户编写的Spark应用程序
任务( Task ):运行在Executor上的工作单元(线程)
作业( Job ):一个作业包含多个RDD及作用于相应RDD上的各种操作
阶段( Stage ):是作业的基本调度单位,一个作业会分为多组任务,每组任务被称为阶段,或者也被称为任务集合,代表了一组关联的、相互之间没有Shuffle依赖关系的任务组成的任务集, 下图为DAG划分Stage过程:


2. 组件关系
当执行一个Application时,Driver会向Yarn申请资源,启动Executor(Worker),并向Executor发送代码和文件,执行任务,任务结束后执行结果会返回给任务控制节点,或者写到HDFS/Hive等。
1 Application = 1 Driver + 多 Job
1 Job(多个 RDD + RDD的操作) = 多个Stage
1 Stage = 多个Task
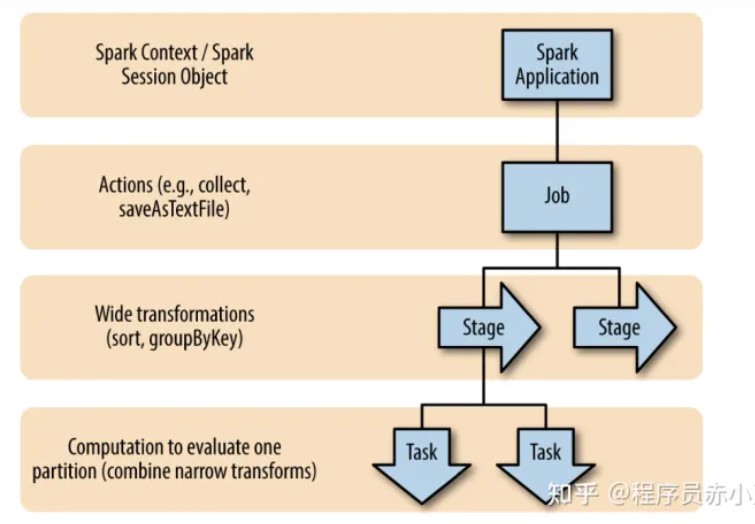
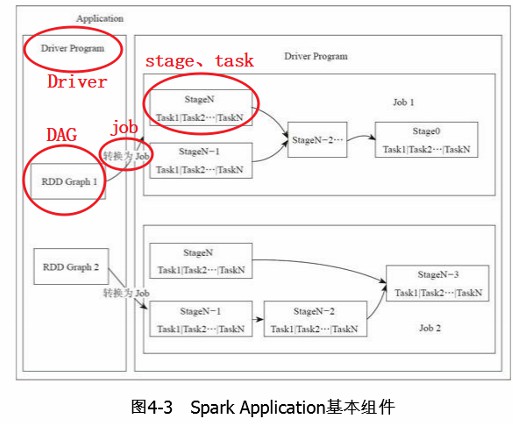
3. 运行流程
(1)概念层级
解释1:
一个Spark提交时,由Driver运行main方法创建一个SparkContext,由SparkContext负责和Yarn的通信、资源的申请、任务的分配和监控等。
SparkContext会向Yarn注册并申请运行Executor的资源。
Yarn为Executor分配资源,启动Executor进程,Executor发送心跳到Yarn上
SparkContext根据RDD的依赖关系构建DAG图,DAG调度解析后将图分解成多个Stage,并计算出之间的依赖关系,将这些Job集提交给Task调度器处理。Executor向SparkContext申请Task,Task调度器将Task分发给Executor运行,同时,SparkContext将Application代码发放给Executor。
任务在Executor上运行,结果反馈给Job调度器,再反馈给DAG调度器,运行完毕后写入数据并释放所有资源。

解释2:
每个 worker 节点包含一个或者多个 executor,一个 executor 中又包含多个 task。task 是真正实现并行计算的最小工作单元。
Driver
Driver 是一个 Java 进程,负责执行 Spark 任务的 main 方法,它的职责有:
执行用户提交的代码,创建 SparkContext 或者 SparkSession
将用户代码转化为Spark任务(Jobs)
- 创建血缘(Lineage),逻辑计划(Logical Plan)和物理计划(Physical Plan)
在 Cluster Manager 的辅助下,把 task 任务分发调度出去
跟踪任务的执行情况
Spark Context/Session
它是由Spark driver创建,每个 Spark 应用对应一个。程序和集群交互的入口。可以连接到 Cluster Manager
Cluster Manager
负责部署整个Spark 集群,包括上面提到的 driver 和 executors。具有以下几种部署模式
- Standalone 模式
- YARN
- Mesos
- Kubernetes
Executor
一个创建在 worker 节点的进程。一个 Executor 有多个 slots(线程) 可以并发执行多个 tasks。
- 负责执行spark任务,把结果返回给 Driver
- 可以将数据缓存到 worker 节点的内存
- 一个 slot 就是一个线程,对应了一个 task
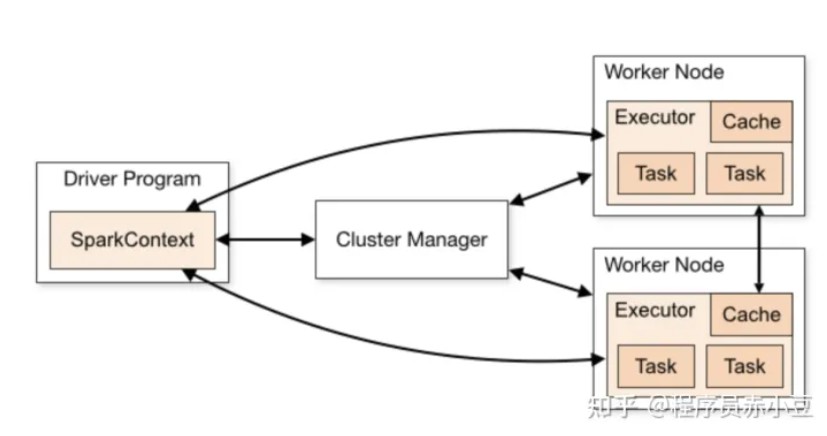
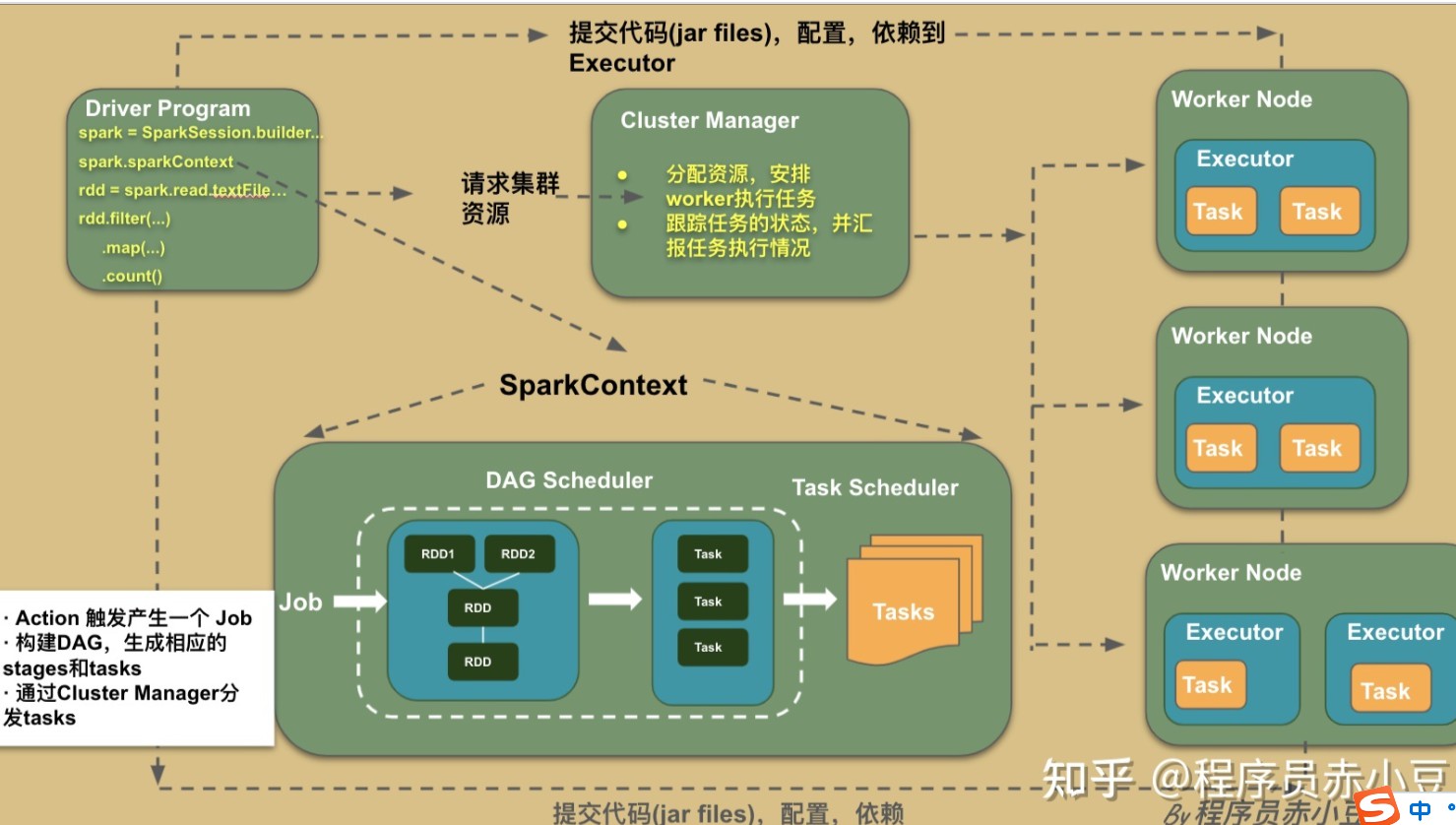
(2)代码层级
Spark 有懒加载的特性,也就是说 Spark 计算按兵不动,直到遇到 action 类型的 operator 的时候才会触发一次计算。
DAG
- Spark Job如何执行,都是由这个 DAG 来管的,包括决定 task 运行在什么节点
Spark Job
- 每个Spark Job 对应一个action
Stages
- 每个 Spark Job 包含一系列 stages
- Stages 按照数据是否需要 shuffle 来划分(宽依赖)
- Stages 之间的执行是串行的(除非stage 间计算的RDD不同)
- 因为 Stages 是串行的,所以 shuffle 越少越好
Tasks
- 每个 stage 包含一系列的 tasks
- Tasks 是并行计算的最小单元
- 一个 stage 中的所有 tasks 执行同一段代码逻辑,只是基于不同的数据块
- 一个 task 只能在一个executor中执行,不能是多个
- 一个 stage 输出的 partition 数量等于这个 stage 执行 tasks 的数量
Partition
- Spark 中 partition(分区) 可以理解为内存中的一个数据集
- 一个 partition 对应一个 task,一个 task 对应 一个 executor 中的一个 slot,一个 slot 对应物理资源是一个线程 thread
- 1 partition = 1 task = 1 slot = 1 thread
(3) spark中Master与Worker区别及Driver与Executor区别
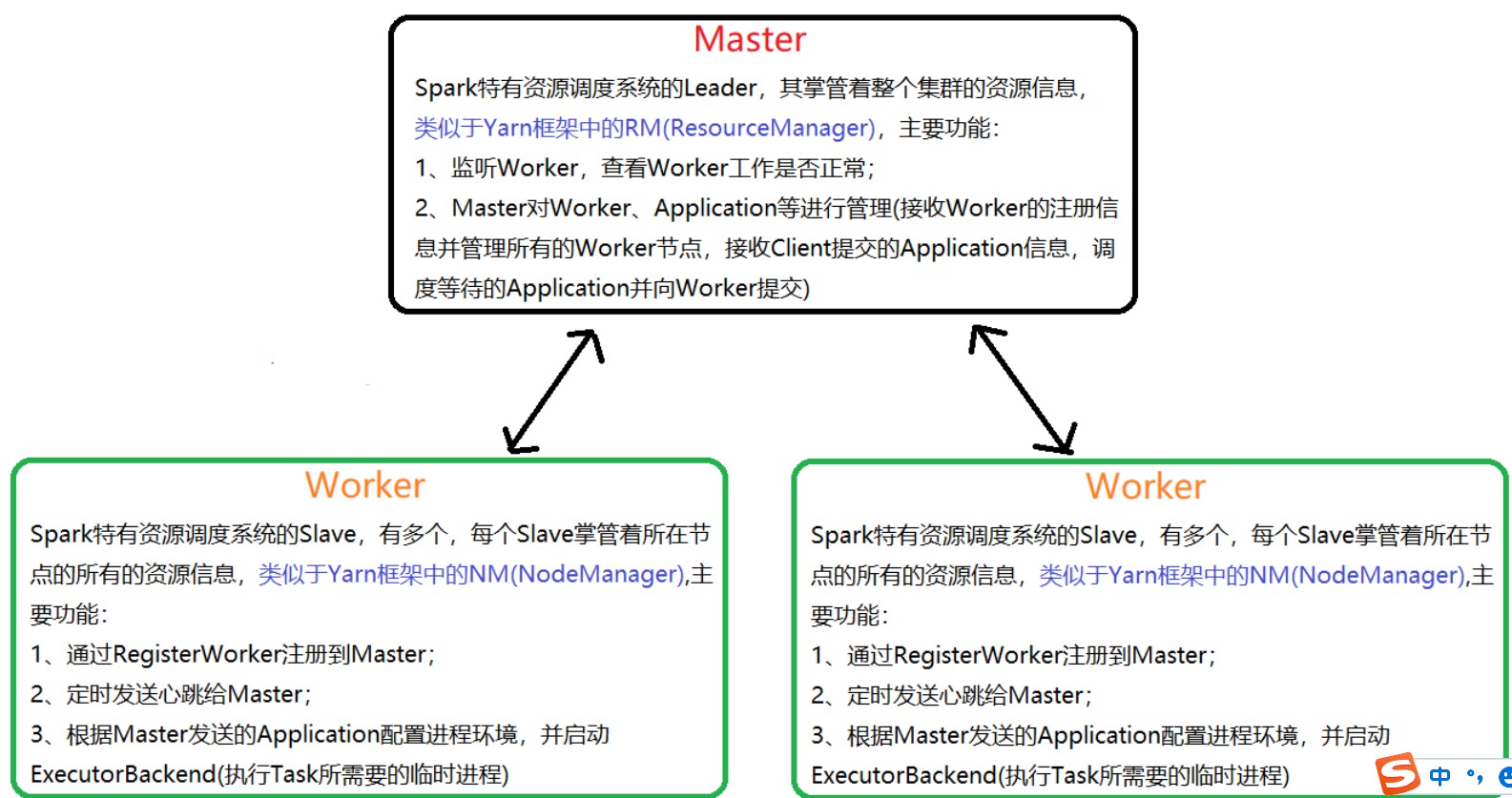
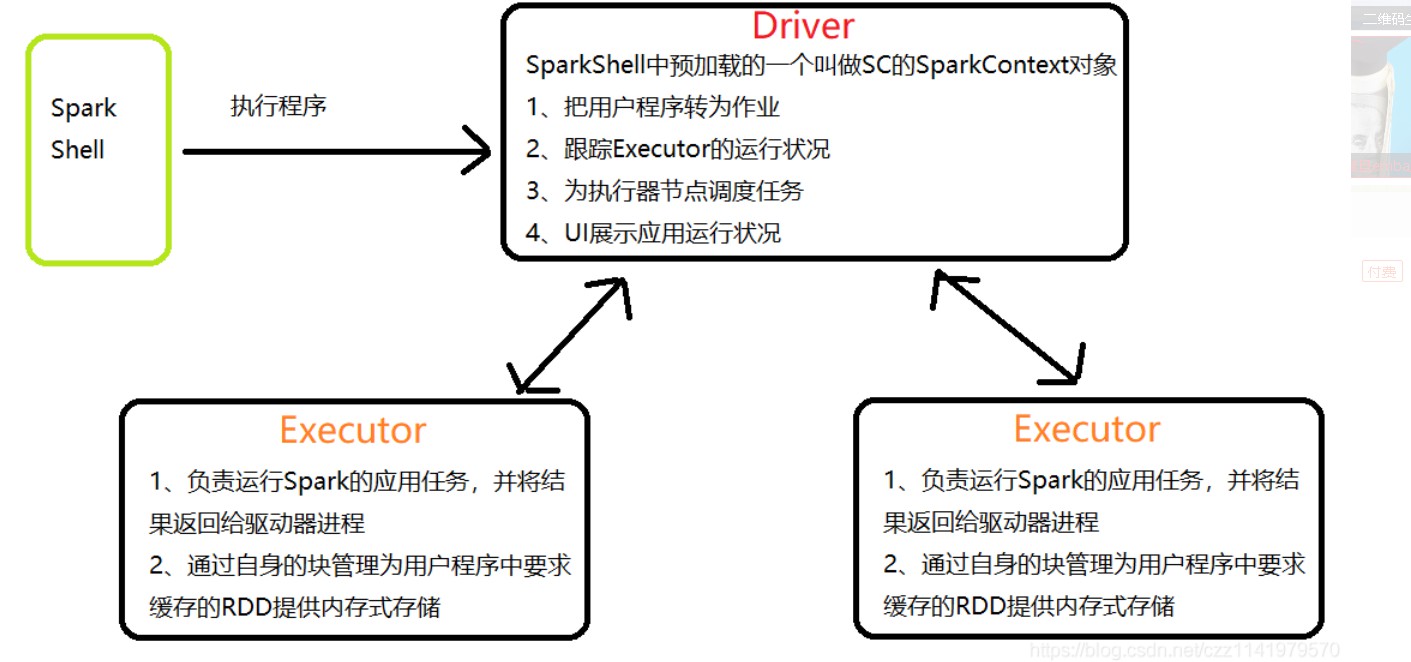
Master和Worker是Spark的守护进程,即Spark在特定模式下正常运行所必须的进程。Driver和Executor是临时程序,当有具体任务提交到Spark集群才会开启的程序。
了解 Spark中的master、worker和Driver、Executor
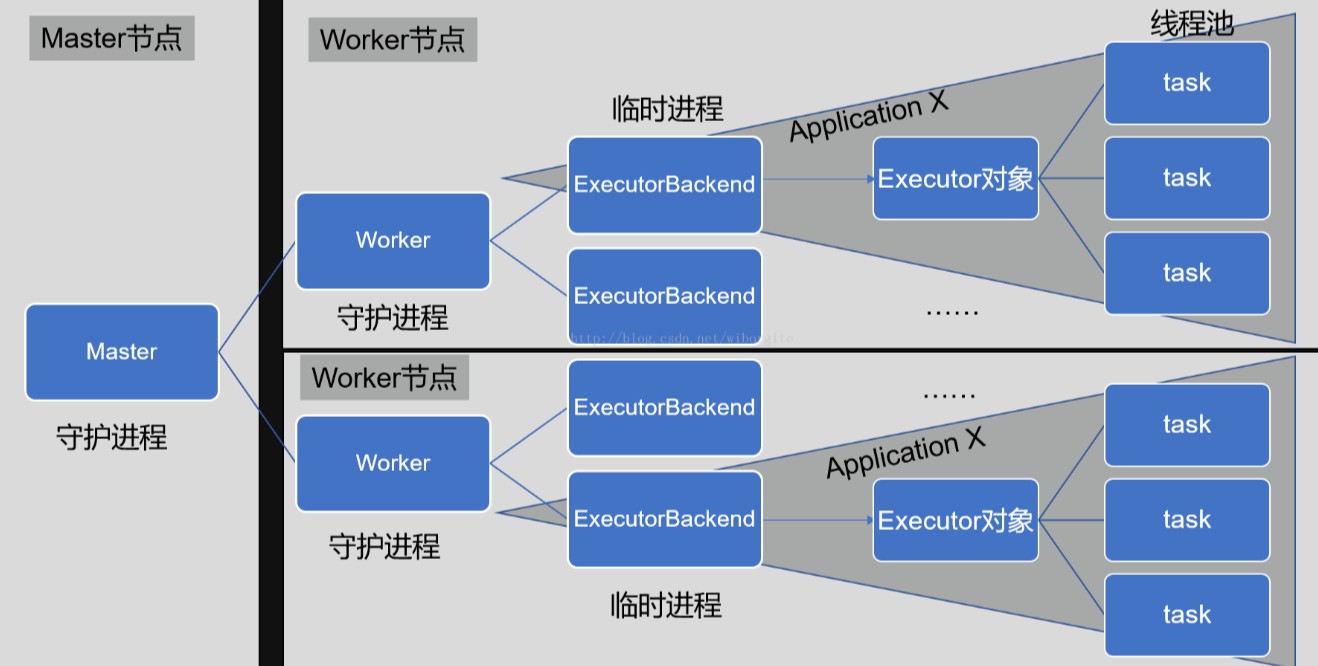
每个Worker上存在一个或者多个ExecutorBackend 进程。每个进程包含一个Executor对象,该对象持有一个线程池,每个线程可以执行一个task。
每个application包含一个 driver 和多个 executors,每个 executor里面运行的tasks都属于同一个application。
每个Worker上存在一个或者多个ExecutorBackend 进程。
每个进程包含一个Executor对象,该对象持有一个线程池,每个线程可以执行一个task
4. DAGScheduler具体流程
DAG负责的是将RDD中的数据依赖划分为不同可以并行的宽依赖task, 这些不同的task集合统称为stage,最后将这些stage推送给TaskScheduler进行调度,DAG的具体划分过程如下所示:
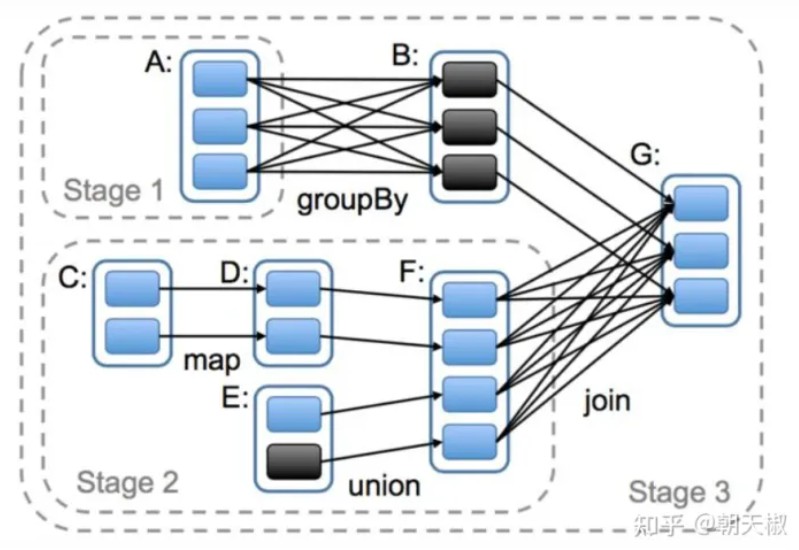
窄依赖经历的是map、filter等操作没有进行相关的shuffle,而宽依赖则通常都是join等操作需要进行一定的shuffle意味着需要打散均匀等操作- 1 stage是触发action的时候 从后往前划分 的,所以本图要从RDD_G开始划分。
- 2 RDD_G依赖于RDD_B和RDD_F,随机决定先判断哪一个依赖,但是对于结果无影响。
- 3 RDD_B与RDD_G属于窄依赖,所以他们属于同一个stage,RDD_B与老爹RDD_A之间是宽依赖的关系,所以他们不能划分在一起,所以RDD_A自己是一个stage1
- 4 RDD_F与RDD_G是属于宽依赖,他们不能划分在一起,所以最后一个stage的范围也就限定了,RDD_B和RDD_G组成了Stage3
- 5 RDD_F与两个爹RDD_D、RDD_E之间是窄依赖关系,RDD_D与爹RDD_C之间也是窄依赖关系,所以他们都属于同一个stage2
- 6 执行过程中stage1和stage2相互之间没有前后关系所以可以并行执行,相应的每个stage内部各个partition对应的task也并行执行
- 7 stage3依赖stage1和stage2执行结果的partition,只有等前两个stage执行结束后才可以启动stage3.
- 8 我们前面有介绍过Spark的Task有两种:ShuffleMapTask和ResultTask,其中后者在DAG最后一个阶段推送给Executor,其余所有阶段推送的都是ShuffleMapTask。在这个案例中stage1和stage2中产生的都是ShuffleMapTask,在stage3中产生的ResultTask。
- 9 虽然stage的划分是从后往前计算划分的,但是依赖逻辑判断等结束后真正创建stage是从前往后的。也就是说如果从stage的ID作为标识的话,先需要执行的stage的ID要小于后需要执行的ID。就本案例来说,stage1和stage2的ID要小于stage3,至于stage1和stage2的ID谁大谁小是随机的,是由前面第2步决定的。
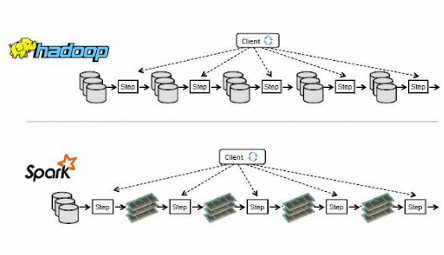
5. MR和spark区别
(1)中间结果输出:
MapReduce:读–处理–写磁盘–读–处理–写磁盘(中间结果落地,即存入磁盘)
spark:读–处理–处理–(需要的时候)写磁盘(中间结果存入内存)
减少落地时间,速度快
(2)数据格式:
MapReduce:从DB中读取数据再处理
spark:采用弹性分布式数据结构RDD存储数据
(3)容错性:
- Spark:采用RDD存储数据,若数据集丢失,可重建。
(4)通用性:
MapReduce:只提供map和reduce两种操作。
spark:提供很多数据集操作类型(transformations、actions)【transformations包括map\filter\
Groupbykey\sort等,action包括reduce、save、collect、lookup等】
(5)执行策略
MapReduce:数据shuffle前需排序
spark:不是所有场景都要排序
6、spark1.x和spark2.x的区别
Spark1.x:采用SparkContext作为进入点
Spark2.x:SparkSession 是 Spark SQL 的入口。
- 采用SparkSession作为进入点,SparkSession可直接读取各种资料源,可直接与Hive元数据沟通,同时包含设定以及资源管理功能。
7. spark 应用执行模式
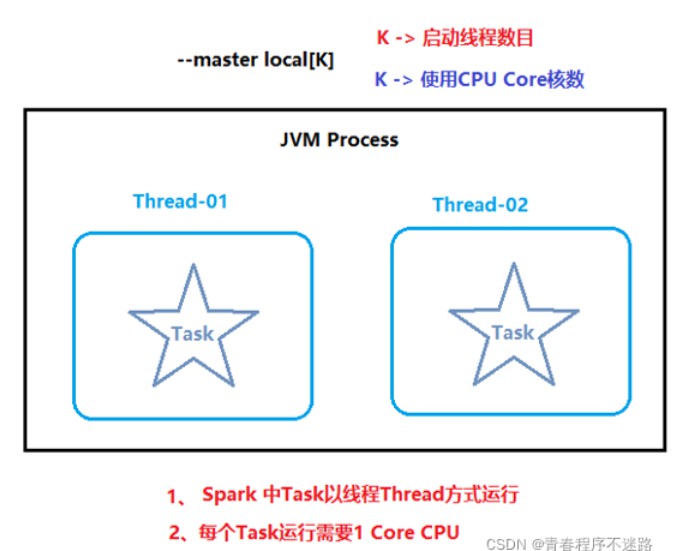
(1)local模式
local 模式主要是用于本地代码测试操作
本质上就是一个单进程程序, 在一个进程中运行多个线程
类似于pandas , 都是一个单进程程序, 无法处理大规模数据, 只需要处理小规模数据
(2)standalone:
Spark Standalone模式:该模式是不借助于第三方资源管理框架的完全分布式模式。Spark 使用自己的 Master 进程对应用程序运行过程中所需的资源进行调度和管理;对于中小规模的 Spark 集群首选 Standalone 模式。目前Spark 在 Standalone 模式下主要是借助 Zookeeper 实现单点故障问题;思想也是类似于 Hbase Master 单点故障解决方案。
(3)YARN
该模式是借助于第三方资源管理框架 Yarn 的完全分布式模式。Spark 作为一个提交程序的客户端将 Job 任务提交到 Yarn 上;然后通过 Yarn 来调度和管理 Job 任务执行过程中所需的资源。需要此模式需要先搭建 Yarn 集群,然后将 Spark 作为 Hadoop 中的一个组件纳入到 Yarn 的调度管理下,这样将更有利于系统资源的共享。
8. 提交任务方法
(1)spark shell
- spark-shell 是 Spark 自带的交互式 Shell 程序,方便用户进行交互式编程,用户可以在该命令行下用 Scala 编写 spark 程序。
应用场景
- 通常是以测试为主
- 所以一般直接以
./spark-shell启动,进入本地模式测试- local方式启动:./spark-shell
- standalone集群模式启动:./spark-shell –master spark://master:7077
- yarn client模式启动:./spark-shell –master yarn-client
(2)spark submit
使用spark 自带的spark-submit工具提交任务
程序一旦打包好,就可以使用 bin/spark-submit 脚本启动应用了。这个脚本负责设置 spark 使用的 classpath 和依赖,支持不同类型的集群管理器和发布模式。
它主要是用于提交编译并打包好的Jar包到集群环境中来运行,和hadoop中的hadoop jar命令很类似,hadoop jar是提交一个MR-task,而spark-submit是提交一个spark任务,这个脚本 可以设置Spark类路径(classpath)和应用程序依赖包,并且可以设置不同的Spark所支持的集群管理和部署模式。 相对于spark-shell来讲它不具有REPL(交互式的编程环境)的,在运行前需要指定应用的启动类,jar包路径,参数等内容。
9. 参数配置:
参数名 参数说明
- -class 应用程序的主类,仅针对 java 或 scala 应用
- -master master 的地址,提交任务到哪里执行,例如 local,spark://host:port, yarn, local
- -deploy-mode 在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client
- -name 应用程序的名称,会显示在Spark的网页用户界面
- -jars 用逗号分隔的本地 jar 包,设置后,这些 jar 将包含在 driver 和 executor 的 classpath 下
- -packages 包含在driver 和executor 的 classpath 中的 jar 的 maven 坐标
- -exclude-packages 为了避免冲突 而指定不包含的 package
- -repositories 远程 repository
- -conf PROP=VALUE 指定 spark 配置属性的值,例如 -conf spark.executor.extraJavaOptions=”-XX:MaxPermSize=256m”
- -properties-file 加载的配置文件,默认为 conf/spark-defaults.conf
- -driver-memory Driver内存,默认 1G
- -driver-java-options 传给 driver 的额外的 Java 选项
- -driver-library-path 传给 driver 的额外的库路径
- -driver-class-path 传给 driver 的额外的类路径
- -driver-cores Driver 的核数,默认是1。在 yarn 或者 standalone 下使用
- -executor-memory 每个 executor 的内存,默认是1G
- -total-executor-cores 所有 executor 总共的核数。仅仅在 mesos 或者 standalone 下使用
- -num-executors 启动的 executor 数量。默认为2。在 yarn 下使用
- -executor-core 每个 executor 的核数。在yarn或者standalone下使用