本文仅做学习总结,如有侵权立删
PySpark的Join
https://zhuanlan.zhihu.com/p/344080090
一、Join方式:
pyspark主要分为以下几种join方式:
- Inner joins (内连接): 两边都有的保持
- Outer joins (外连接):两边任意一边有的保持
- Left outer joins (左外连接):只保留左边有的records
- Right outer joins (右外连接):只保留右边有的records
- Left semi joins (左半连接):只保留在右边记录里出现的左边的records
- Left anti joins (左反连接):只保留没出现在右边记录里的左边records(可以用来做过滤)
- natural join(自然连接):通过隐式匹配两个数据集之间具有相同名称的列来执行连接)
- cross join(笛卡尔连接):将左侧数据集的每一行与右侧数据集中的每一行匹配,结果行数很多。
##二、使用方式和例子
下面造个数据集来看看这些join的例子
1 | person = spark.createDataFrame([ |
Inner Joins
1 | # in Python |
Outer Joins
Outerjoins evaluate the keys in both of the DataFrames or tables and includes (and joins together) the rows that evaluate to true or false. If there is no equivalent row in either the left or right DataFrame, Spark will insert
null:
1 | joinType = "outer" |
Left Outer Joins
Leftouter joins evaluate the keys in both of the DataFrames or tables and includes all rows from the left DataFrame as well as any rows in the right DataFrame that have a match in the left DataFrame. If there is no equivalent row in the right DataFrame, Spark will insert
null:
1 | joinType = "left_outer" |
Right Outer Joins
Rightouter joins evaluate the keys in both of the DataFrames or tables and includes all rows from the right DataFrame as well as any rows in the left DataFrame that have a match in the right DataFrame. If there is no equivalent row in the left DataFrame, Spark will insert
null:
1 | joinType = "right_outer" |
Left Semi Joins 用作数据筛选(include 方式)
Semijoins are a bit of a departure from the other joins. They do not actually include any values from the right DataFrame. They only compare values to see if the value exists in the second DataFrame. If the value does exist, those rows will be kept in the result, even if there are duplicate keys in the left DataFrame. Think of left semi joins as filters on a DataFrame, as opposed to the function of a conventional join:
1 | joinType = "left_semi" |
Left Anti Joins 用作数据筛选(exclude的方式)
Leftanti joins are the opposite of left semi joins. Like left semi joins, they do not actually include any values from the right DataFrame. They only compare values to see if the value exists in the second DataFrame. However, rather than keeping the values that exist in the second DataFrame, they keep only the values thatdo nothave a corresponding key in the second DataFrame. Think of anti joins as a
NOT INSQL-style filter
1 | joinType = "left_anti" |
三、常见问题和解决方案
1. 处理重复列名:两张表如果存在相同列名??
方法1:采用不同的连接表达式:
当有两个同名的键时,将连接表达式从布尔表达式更改为字符串或序列,这会在连接过程中自动删除其中一个列。
1 | a.join(b, 'id') # 不写成a.join(b , a['id']==b['id']) |
方法2:连接后删除列,采用drop
1 | a.join(b, a['id']==b['id']).drop(a.id) |
方法3:在连接前重命名列,采用withColumnRenamed
1 | a = a.withColumnRenamed('id1', F.col('id')) |
四、Spark如何执行连接
两个核心模块:点对点通信模式和逐点计算模式
大表和大表的连接
- shuffle join :每个节点都与所有其他节点进行通信,并根据哪个节点具有某些键来共享数据。由于网络会因通信量而阻塞,所以这种方式很耗时,特殊是如果数据没有合理分区的情况下。
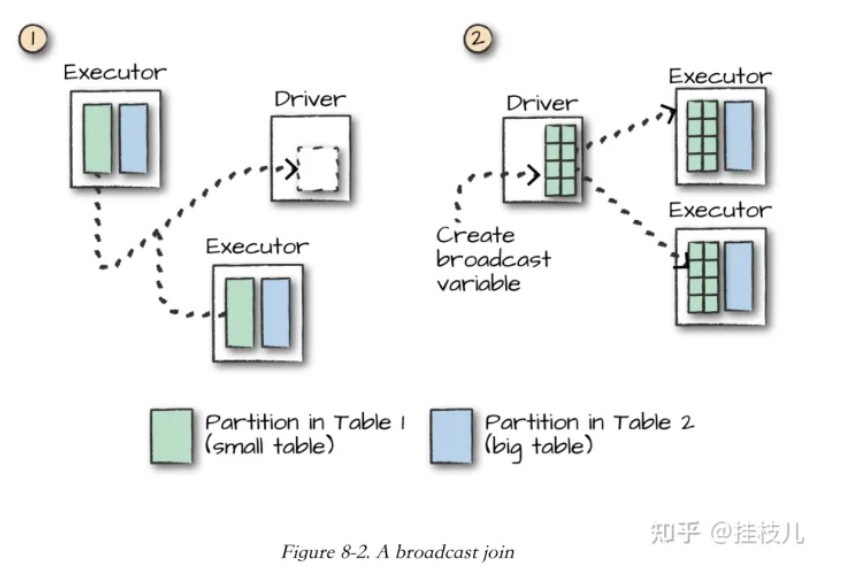
大表与小表连接
broadcast join:当表的大小足够小以便能够放入单个节点内存中且还有空闲空间的时候,可优化join。
把数据量较小的DataFrame复制到集群中的所有工作节点上,只需在开始时执行一次,然后让每个工作节点独立执行作业,而无需等待其他工作节点,也无需与其他工作节点通信。