本文仅做学习总结,如有侵权立删
持久化
1. 引言

查看上面那段伪代码,两个count触发算子会产生两个job, 那么,这两个job会往回去找errors,lines这两个rdd,最后到磁盘上拿数据。也就是每个job都会去读一遍磁盘,这里可以做优化, 将errors这个rdd保存到内存中, 然后第一个count会去磁盘度数, 但第二个count直接可以从内存中读数据了。
控制算子有三种,cache,persist,checkpoint,以上算子都可以将RDD持久化,持久化的单位是partition。
cache、persist和checkpoint都是懒执行的。
必须有一个action类算子触发执行。checkpoint算子不仅能将RDD持久化到磁盘,还能切断RDD之间的依赖关系
RDD 可以使用 persist() 方法或 cache() 方法进行持久化。数据将会在第一次 action 操作时进行计算,并缓存在节点的内存中。Spark 的缓存具有容错机制,如果一个缓存的 RDD 的某个分区丢失了,Spark 将按照原来的计算过程,自动重新计算并进行缓存。
在 shuffle 操作中(例如 reduceByKey),即便是用户没有调用 persist 方法,Spark 也会自动缓存部分中间数据。这么做的目的是,在 shuffle 的过程中某个节点运行失败时,不需要重新计算所有的输入数据。如果用户想多次使用某个 RDD,强烈推荐在该 RDD 上调用 persist 方法。
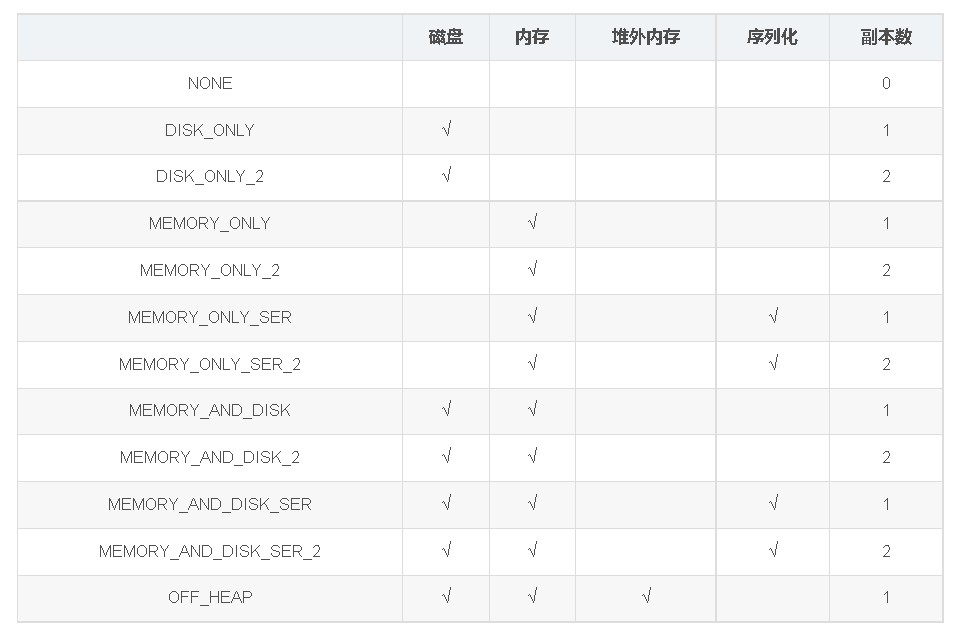
存储级别
可以看到StorageLevel类的主构造器包含了5个参数:
- useDisk:使用硬盘(外存)
- useMemory:使用内存
- useOffHeap:使用堆外内存,这是Java虚拟机里面的概念,堆外内存意味着把内存对象分配在Java虚拟机的堆以外的内存,这些内存直接受操作系统管理(而不是虚拟机)。这样做的结果就是能保持一个较小的堆,以减少垃圾收集对应用的影响。
- deserialized:反序列化,其逆过程序列化(Serialization)是java提供的一种机制,将对象表示成一连串的字节;而反序列化就表示将字节恢复为对象的过程。序列化是对象永久化的一种机制,可以将对象及其属性保存起来,并能在反序列化后直接恢复这个对象
- replication:备份数(在多个节点上备份)
每个持久化的 RDD 可以使用不同的存储级别进行缓存,例如,持久化到磁盘、已序列化的 Java 对象形式持久化到内存(可以节省空间)、跨节点间复制、以 off-heap 的方式存储在 Tachyon。这些存储级别通过传递一个 StorageLevel 对象给 persist() 方法进行设置。
详细的存储级别介绍如下:
- MEMORY_ONLY : 将 RDD 以反序列化 Java 对象的形式存储在 JVM 中。如果内存空间不够,部分数据分区将不再缓存,在每次需要用到这些数据时重新进行计算。这是默认的级别。
- MEMORY_AND_DISK : 将 RDD 以反序列化 Java 对象的形式存储在 JVM 中。如果内存空间不够,将未缓存的数据分区存储到磁盘,在需要使用这些分区时从磁盘读取。
- MEMORY_ONLY_SER : 将 RDD 以序列化的 Java 对象的形式进行存储(每个分区为一个 byte 数组)。这种方式会比反序列化对象的方式节省很多空间,尤其是在使用 fast serializer时会节省更多的空间,但是在读取时会增加 CPU 的计算负担。
- MEMORY_AND_DISK_SER : 类似于 MEMORY_ONLY_SER ,但是溢出的分区会存储到磁盘,而不是在用到它们时重新计算。
- DISK_ONLY : 只在磁盘上缓存 RDD。
- MEMORY_ONLY_2,MEMORY_AND_DISK_2,等等 : 与上面的级别功能相同,只不过每个分区在集群中两个节点上建立副本。
- OFF_HEAP): 类似于 MEMORY_ONLY_SER ,但是将数据存储在 off-heap memory,这需要启动 off-heap 内存。(Off-heap是指在堆外内存)
1 | val NONE = new StorageLevel(false, false, false, false) |
如何选择存储级别
Spark 的存储级别的选择,核心问题是在内存使用率和 CPU 效率之间进行权衡。建议按下面的过程进行存储级别的选择 :
- 如果使用默认的存储级别(MEMORY_ONLY),存储在内存中的 RDD 没有发生溢出,那么就选择默认的存储级别。默认存储级别可以最大程度的提高 CPU 的效率,可以使在 RDD 上的操作以最快的速度运行。
- 如果内存不能全部存储 RDD,那么使用 MEMORY_ONLY_SER,并挑选一个快速序列化库将对象序列化,以节省内存空间。使用这种存储级别,计算速度仍然很快。
- 除了在计算该数据集的代价特别高,或者在需要过滤大量数据的情况下,尽量不要将溢出的数据存储到磁盘。因为,重新计算这个数据分区的耗时与从磁盘读取这些数据的耗时差不多。
- 如果想快速还原故障,建议使用多副本存储级别(例如,使用 Spark 作为 web 应用的后台服务,在服务出故障时需要快速恢复的场景下)。所有的存储级别都通过重新计算丢失的数据的方式,提供了完全容错机制。但是多副本级别在发生数据丢失时,不需要重新计算对应的数据库,可以让任务继续运行。
2. persist
persist使用场景:
- 某个步骤计算非常耗时,需要进行persist持久化
- 计算链条非常长,重新恢复要算很多步骤
- 需要checkpoint的RDD最好进行persist,checkpoint机制会在job执行完成之后根据DAG向前回溯,找到需要进行checkpoint的RDD,另起一个job来计算该RDD,将计算结果存储到HDFS,如果在job执行的过程中对该RDD进行了persist,那么进行checkpoint会非常快
- shuffle之前进行persist,Spark默认将数据持久化到磁盘,自动完成,无需干预
- shuffle之后为什么要persist,shuffle要进性网络传输,风险很大,数据丢失重来,恢复代价很大
3. cache
RDD的cache和persist的区别
cache()调用的persist(),是使用默认存储级别的快捷设置方法(MEMORY_ONLY)
通过源码可以看出cache()是persist()的简化方式,调用persist的无参版本,也就是调用persist(StorageLevel.MEMORY_ONLY),cache只有一个默认的缓存级别MEMORY_ONLY,即将数据持久化到内存中,而persist可以通过传递一个 StorageLevel 对象来设置其它的缓存级别。
4. unpersist 释放缓存:
Spark 自动监控各个节点上的缓存使用率,并以最近最少使用的方式(LRU)将旧数据块移除内存。如果想手动移除一个 RDD,而不是等待该 RDD 被 Spark 自动移除,可以使用 RDD.unpersist() 方法
注意:如果缓存的RDD之间有依赖关系,比如
val rdd_a = df.persist
val rdd_b = rdd_a.filter.persist
val rdd_c = rdd_b.map.persist
在用unpersist清理缓存时,当首先清理rdd_a时,会重建rdd_b和rdd_c的缓存,如果数据量巨大,这个过程可能花费很长时间,即使rddb和rdd_c后面也即将被清理,但是重建过程也会进行,可能会出现一个现象,所有job都以完成,但是任务长时间处于RUNNING状态,这可能就是因为最后再清理缓存时又会把依赖于它的RDD再重算一遍。这时可以只用使用spark.sharedState.cacheManager.uncacheQuery(df, cascade = true, blocking = false)来全部释放,参数cascade 表示是否清理所有引用此RDD的其他RDD,以下是unpersist的源码,可以一目了然
1 | def unpersist(blocking: Boolean): this.type = { |
5. checkpoint
checkpoint将RDD持久化到磁盘,还可以切断RDD之间的依赖关系
checkpoint 的执行原理
- 当RDD的job执行完毕后,会从finalRDD从后往前回溯。
- 当回溯到某一个RDD调用了checkpoint方法,会对当前的RDD做一个标记。
- Spark框架会自动启动一个新的job,重新计算这个RDD的数据,将数据持久化到HDFS上。
优化:对RDD执行checkpoint之前,最好对这个RDD先执行cache,这样新启动的job只需要将内存中的数据拷贝到HDFS上就可以,省去了重新计算这一步
解释:cache 机制是每计算出一个要 cache 的 partition 就直接将其 cache 到内存了。但 checkpoint 没有使用这种第一次计算得到就存储的方法,而是等到 job 结束后另外启动专门的 job 去完成 checkpoint 。也就是说需要 checkpoint 的 RDD 会被计算两次。因此,在使用 rdd.checkpoint() 的时候,建议加上 rdd.cache(),这样第二次运行的 job 就不用再去计算该 rdd 了,直接读取 cache 写磁盘。
(1)cache 和 checkpoint 之间有一个重大的区别,
cache 将 RDD 以及 RDD 的血统(记录了这个RDD如何产生)缓存到内存中,当缓存的 RDD 失效的时候(如内存损坏),它们可以通过血统重新计算来进行恢复。但是 checkpoint 将 RDD 缓存到了 HDFS 中,同时忽略了它的血统(也就是RDD之前的那些依赖)。为什么要丢掉依赖?因为可以利用 HDFS 多副本特性保证容错!
(2)persist与checkpoint的区别
rdd.persist(StorageLevel.DISK_ONLY) 与 checkpoint 也有区别。前者虽然可以将 RDD 的 partition 持久化到磁盘,但该 partition 由 blockManager 管理。一旦 driver program 执行结束,也就是 executor 所在进程 CoarseGrainedExecutorBackend stop,blockManager 也会 stop,被 cache 到磁盘上的 RDD 也会被清空(整个 blockManager 使用的 local 文件夹被删除)。
而 checkpoint 将 RDD 持久化到 HDFS 或本地文件夹,如果不被手动 remove 掉,是一直存在的,也就是说可以被下一个 driver program 使用,而 cached RDD 不能被其他 dirver program 使用。
总结
Spark相比Hadoop的优势在于尽量不去持久化,所以使用 pipeline,cache 等机制。用户如果感觉 job 可能会出错可以手动去 checkpoint 一些 critical 的 RDD,job 如果出错,下次运行时直接从 checkpoint 中读取数据。唯一不足的是,checkpoint 需要两次运行 job。