本文仅做学习总结,如有侵权立删
Spark SQL简介
1、什么是SQL
结构化查询语言:一种表示数据关系操作的特定领域语言。
Spark2.0发布了一个支持Hive操作的超集,并提供了一个能够同时支持ANSI SQL(标准SQL)和HiveSQL的原生SQL解析器。
SparkSession新的起始点
在老的版本中,SparkSQL提供两种SQL查询起始点:一个叫SQLContext,用于Spark自己提供的SQL查询;一个叫HiveContext,用于连接Hive的查询。
SparkSession是Spark最新的SQL查询起始点,实质上是SQLContext和HiveContext的组合,所以在SQLContext和HiveContext上可用的API在SparkSession上同样是可以使用的。SparkSession内部封装了sparkContext,所以计算实际上是由sparkContext完成的表存储两类重要的信息:表内数据和表的有关数据,也就是元数据。
- 托管表: 让Spark管理一组文件和数据的元数据
当您从磁盘上的文件定义表时,您正在定义一个非托管表。
“拥有”其数据,表定义 (元数据) 以及表数据都通过元数据系统进行管理。 托管表在其架构和数据之间提供一致性,如果删除了托管表,则它包含的数据 也将被删除。
- 非托管表: Spark只管理表的元数据
外部表是在元数据系统中提供表架构的表,但仅引用来自元数据系统控件的外部数据的表。 因此,在创建表后,无法保证表架构与数据一致。 无需通过外部表即可更改外部数据。 如果更改或删除外部表,基础数据不会受到影响或删除。
2. Dataframe和SQL互转
(1)createOrReplaceTempView:对DataFrame创建一个临时表
(2)df.createGlobalTempView:对于DataFrame创建一个全局表
1 | # Dataframe转SQL,对DataFrame创建一个临时表 |
3. Catalog
catalog: 指的是所有的database目录
Spark SQL中的最高抽象是Catalog。Catalog是存储关于表中存储的数据以及其他有用的东西(如数据库、表、函数和视图)的元数据的抽象。
Catalog位于org.apache.spark.sql.catalog.Catalog包中,包含许多有用的函数,用于列出表、数据库和函数。我们将很快讨论所有这些事情。它对用户来说非常容易理解,因此我们将省略这里的代码示例,但它实际上只是另一个SparkSQL的编程接口。本章只显示正在执行的SQL;因此,如果您正在使用编程接口,请记住您需要将所有内容封装在一个spark.sql()函数中,执行相关代码。
4. 表
(1)创建表:create table
- 从多种数据源创建表:

USING 和 STORED AS
前面示例中的USING语法规范非常重要。如果不指定格式,Spark将默认为Hive SerDe配置。这对将来的读取和写入有性能影响,因为Hive SerDes比Spark的本地序列化慢得多。Hive用户还可以使用STORED AS语法来指定这应该是一个Hive表。
- 也可以从查询中创建一个表:
1 | CREATE TABLE flights_from_select USING parquet AS SELECT * FROM flights |
此外,只有在表当前不存在时,才可以指定创建表:
在本例中,我们创建了一个与hive兼容的表,因为我们没有通过USING显式指定格式。我们还可以这样做:
1 | CREATE TABLE IF NOT EXISTS flights_from_select AS SELECT * FROM flights |
根据分区的控制数据布局:
1 | CREATE TABLE partitioned_flights USING parquet |
这些表甚至可以通过会话在Spark中使用;Spark中目前不存在临时表。您必须创建一个临时视图.
(2)创建外部表:create EXTERNAL table
- create EXTERNAL table:创建一个外部表
您可以通过运行以下命令来使用任何已经定义的文件创建外部表:

您还可以从select子句创建一个外部表:

(3)插入数据到表
标准SQL:INSERT INTO
1 | INSERT INTO flights_from_select |
如果只希望写入某个分区,可以选择提供分区规范。注意,写操作也会遵循分区模式(这可能导致上面的查询运行得非常慢);但是,它只会添加额外的文件到目的分区:
1 | INSERT INTO partitioned_flights |
(4) 查看表元数据: DESCRIBE TABLE
我们在前面看到,可以在创建表时添加注释。你可以通过描述表元数据来查看,它会显示相关的注释:
1 | DESCRIBE TABLE flights_csv |
您还可以使用以下方法查看数据的分区方案(但是,请注意,这只适用于分区表):
1 | SHOW PARTITIONS partitioned_flights |
(5)刷新表元数据: REFRESH TABLE 、REPAIR TABLE
维护表元数据是确保从最新数据集读取数据的一项重要任务。有两个命令用于刷新表元数据。REFRESH TABLE刷新与该表关联的所有缓存条目(本质上是文件)。如果该表以前缓存过,那么下次扫描时它将被延迟缓存:
另一个相关命令是REPAIR TABLE,它刷新catalog中为给定表维护的分区。这个命令的重点是收集新的分区信息,例如手工写一个新的分区,需要相应地修复表:
1 | MSCKREPAIR TABLE partitioned_flights |
(6) 删除表:drop table
1 | 您不能delete表:您只能“drop”它们。可以使用drop关键字删除表。如果删除托管表(例如flights_csv),数据和表定义都将被删除: |
1 | DROP TABLE flights_csv; |
如果您试图删除不存在的表,您将收到一个错误。若要仅删除已经存在的表,请使用DROP TABLE IF EXISTS:
1 | DROP TABLE IF EXISTS flights_csv; |
- 删除非托管表
1 | 如果您正在删除一个非托管表(例如,hive_flights),则不会删除任何数据,但您将不再能够通过表名引用该数据。 |
(7)缓存表:cache和uncache
就像DataFrames一样,您可以缓存和不缓存表。您只需使用以下语法指定要使用哪个表:
1 | # 缓存表 |
5、视图
创建了表之后,还可以定义视图。视图在现有表的之上定义一组转换(基本上就是保存的查询计划),这对于组织或重用查询逻辑非常方便。Spark有几个不同的视图概念。视图可以是全局级别的,可以设置为数据库级别,也可以是会话级别。
(1)创建视图: CREATE VIEW
对于最终用户来说,视图显示为表,只是在查询时对源数据执行转换,而不是将所有源数据重写到新的位置。这可能是一个filter、select,也可能是一个更大的group BY或ROLLUP。例如,在下面的例子中,我们创建了一个目的地为美国的视图,以便只看到这些航班:
- 创建视图: CREATE VIEW
1 | CREATE VIEW just_usa_view AS SELECT * FROM flights WHERE dest_country_name = 'United States' |
创建临时视图: CREATE TEMP VIEW
这些视图只在当前会话期间可用,并且不注册到数据库:
1 | CREATE TEMP VIEW just_usa_view_temp AS SELECT * FROM flights WHERE dest_country_name = 'United States' |
- 创建全局临时视图: CREATE GLOBAL TEMP VIEW
全局临时视图的解析与数据库无关,可以在整个Spark应用程序中查看,但在会话结束时将它们删除:
1 | CREATE GLOBAL TEMP VIEW just_usa_global_view_temp AS SELECT * FROM flights WHERE dest_country_name = 'United States'SHOW TABLES |
覆盖视图:CREATE OR REPLACE TEMP VIEW
还可以使用下面示例中所示的关键字指定,如果一个视图已经存在,则希望覆盖该视图。我们可以覆盖临时视图和常规视图:
1 | CREATE OR REPLACE TEMP VIEW just_usa_view_temp AS SELECT * FROM flights WHERE dest_country_name = 'United States' |
查询视图
1
SELECT * FROM just_usa_view_temp
视图实际上是一个转换,Spark只在查询时执行它。这意味着它只会在您实际查询表之后应用该过滤器(而不是更早)。
实际上,视图相当于从现有DataFrame创建一个新的DataFrame。实际上,您可以通过比较Spark DataFrames和Spark SQL生成的查询计划来了解这一点。
删除视图: DROP VIEW IF EXISTS
可以像删除表一样删除视图;只需指定要删除的是视图而不是表。删除视图和删除表的主要区别在于,对于视图,不删除底层数据,只删除视图定义本身:
1 | DROP VIEW IF EXISTS just_usa_view; |
6、数据库
查看所有数据库:SHOW DATABASES
创建数据库
创建数据库的模式与您在本章前面看到的相同;但是,这里使用CREATE DATABASE关键字:
1
CREATE DATABASE some_db
您可能想要设置一个数据库来执行某个查询。要做到这一点,使用use关键字后面跟着数据库名称:
1
USE some_db
查看当前使用的数数据库
1 | SELECT current_database() |
- 删除数据库: DROP DATABASE
1 | DROP DATABASE IF EXISTS some_db; |
7、高级主题
Spark SQL中有三种核心的复杂类型:struct、list和map。
(1)Struct
struct更类似于map。它们提供了在Spark中创建或查询嵌套数据的方法。要创建一个,你只需要用括号括起一组列(或表达式):

- 查询Struct
1 | select country.DEST_COUNTRY_NAME, count FROM nested_date |
(2)List
有几种方法可以创建数组或值列表。
使用collect_list函数,它创建一个值列表。
使用函数collect_set,它创建一个没有重复值的数组。
这两个都是聚合函数,因此只能在聚合中指定:

- 手动创建数组

- 查询列表索引:[0]

将数组转换回行。使用explode函数
- 建视图

- 拆行
现在让我们将复杂类型分解为数组中每个值对应的结果中的一行。DEST_COUNTRY_NAME将对数组中的每个值进行复制,执行与原始collect完全相反的操作,并返回到原始DataFrame:

(3)查看Spark SQL中的函数列表:
SHOW FUNCTIONS: 查看Spark SQL中的函数列表
SHOW SYSTEM FUNCTIONS:指示是否希望查看系统函数(即Spark内置函数)以及用户函数:
SHOW USER FUNCTIONS: 用户函数是由您或其他共享Spark环境的人定义的。
SHOW FUNCTIONS “s*“: 通过传递带有通配符(*)的字符串来过滤所有SHOW命令。所有以“s”开头的函数:;
SHOW FUNCTIONS LIKE “collect*”: 选择包含LIKE关键字
- 自定义函数

可以通过Hive CREATE TEMPORARY FUNCTION语法注册函数。
(4)子查询
如果你想看到你的航班是否会把你从你当前所在国家带回来,你可以通过检查是否有这样航班:以当前所在国家为起飞点,以带回国家为目的地:

EXISTS只检查子查询中的一些存在性,如果有值,返回true。你可以通过把NOT运算符放在它前面来翻转它。这就相当于找到了一架飞往你无法返回目的地的航班!

SQL配置
您可以在应用程序初始化时或在应用程序执行过程中设置这些参数(就像我们在本书中看到的shuffle分区一样)。
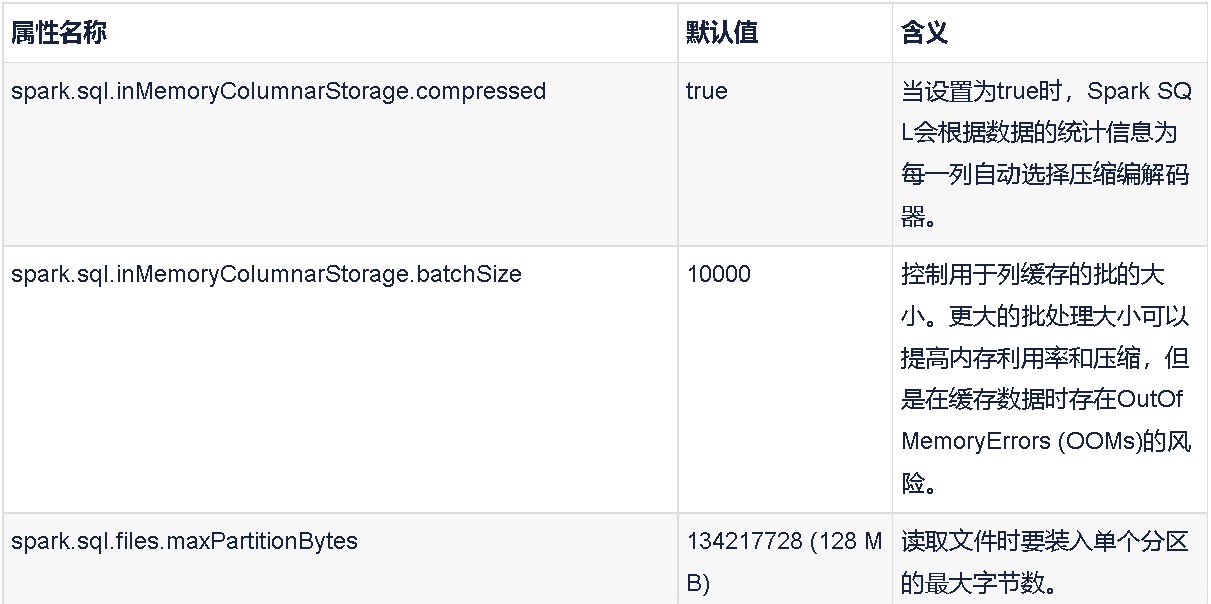
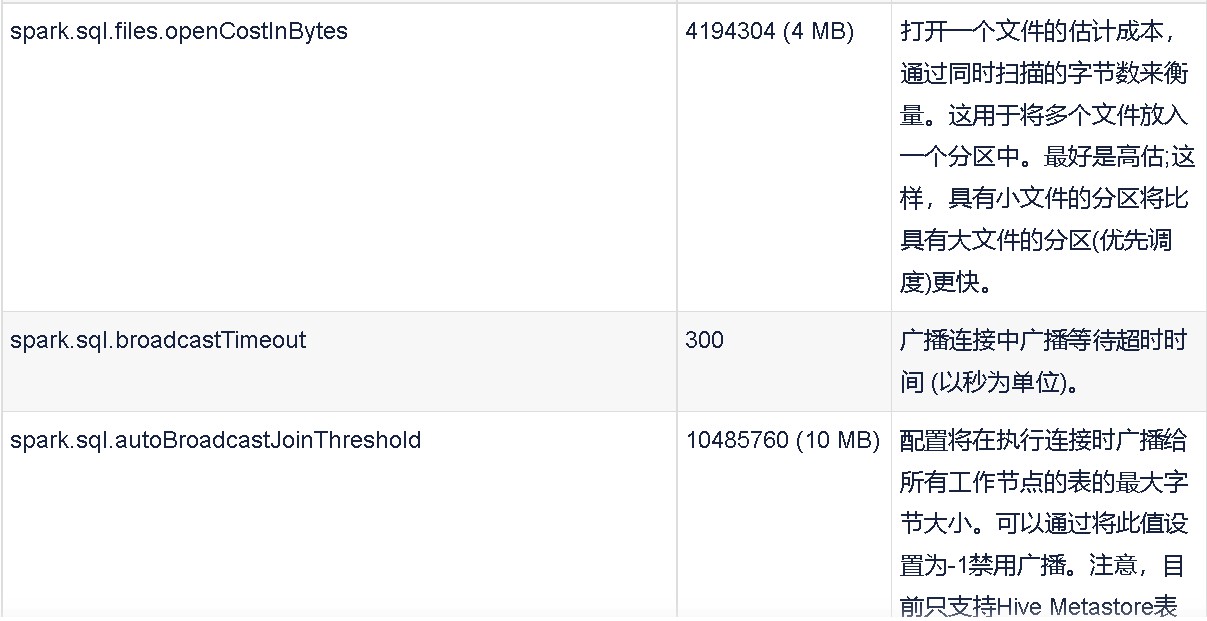
spark.sql.shuffle.partitions 200 配置在为连接或聚合shuffle数据时要使用的分区数。
您只能以这种方式设置Spark SQL配置,但是下面是如何设置shuffle分区:SETspark.sql.shuffle.partitions=20