本文仅做学习总结,如有侵权立删
一、设计理念
1. 图的定义和运行完全分开,采用符号式编程
- 先定义各种变量
- 建立一个数据流图
- 在数据流图中规定各个变量之间的计算关系
- 对数据流图进行编译
- 直至真正的输入数据进入图中,才形成数据流输出值。
2. 运算都放在图中,图的运行只发生在session中。
- 开启session后,可以用数据去填充节点,进行运算
- 关闭会话后,就不能进行计算了
二、运行流程
运行流程主要有2步:构造模型和训练
模型图:但没发生实际运算。【Tensor,Variable,placeholder】
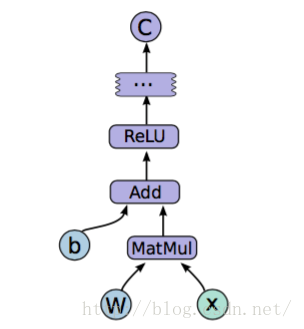
- 训练:有实际数据输入,梯度计算等操作。【session】
三、编程模型
1 | # 导包 |
1 | # 创建常量vec1和vec2 |
1 | # 创建矩阵相乘的操作 |
In [10]:
1 | # 创建会话Session并输出计算的结果 |